One of the biggest differences between experimental AI demos and production AI systems is reliability.
In real-world environments, AI agents eventually fail.
They may:
- generate invalid outputs,
- call tools incorrectly,
- hit API rate limits,
- produce hallucinations,
- lose workflow state,
- or fail during orchestration.
This is completely normal.
The key question is not:
“Will the agent fail?”
The real question is:
“How does the system recover when failure happens?”
This is where retry logic and failure recovery become critically important.
Modern AI systems increasingly require:
- resilience,
- fault tolerance,
- recovery workflows,
- retries,
- and observability.
Frameworks like PydanticAI strongly support these ideas through:
- validation,
- structured outputs,
- typed schemas,
- and controllable workflows.
This article explains:
- why AI agents fail,
- how retry systems work,
- common recovery strategies,
- and how Python developers can build more resilient AI systems.
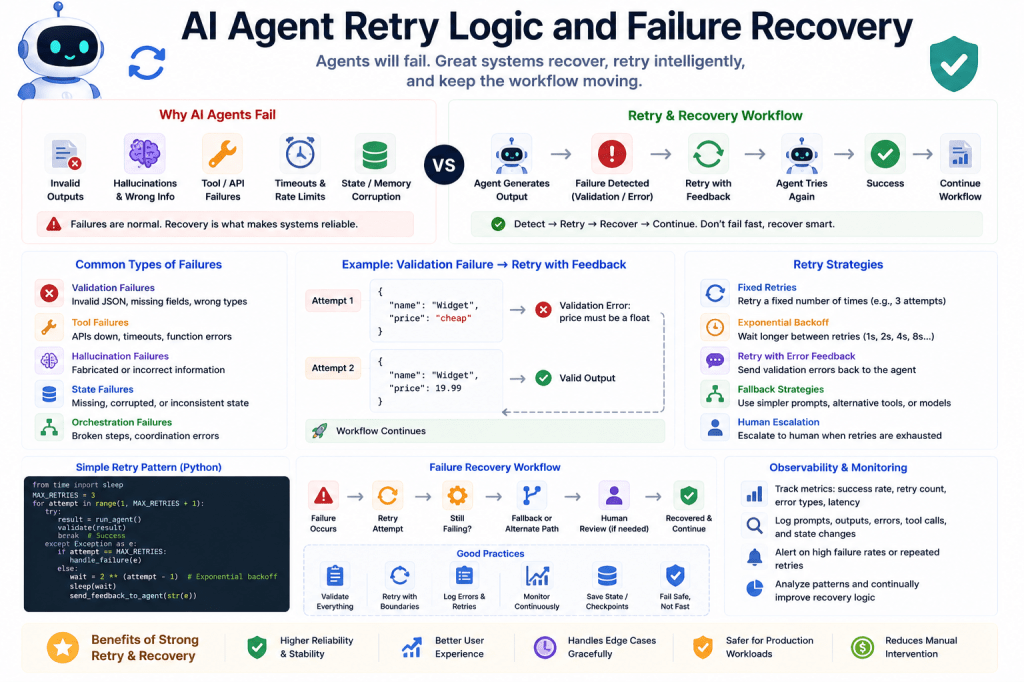
Why AI Agents Fail
AI systems are probabilistic systems.
Unlike traditional deterministic software:
- outputs can vary,
- reasoning can drift,
- and execution may become unpredictable.
This creates many potential failure points.
Common AI Agent Failures
AI agents commonly fail because of:
- invalid outputs,
- hallucinations,
- missing fields,
- API failures,
- timeout errors,
- bad tool calls,
- malformed JSON,
- memory corruption,
- or workflow interruptions.
Production systems must handle these failures gracefully.
Example Failure Scenario
Suppose an agent generates:
{ "price": "cheap"}
But your schema expects:
price: float
Validation fails.
Without retry logic:
- the workflow crashes.
With recovery logic:
- the system retries safely.
What Is Retry Logic?
Retry logic means:
- attempting execution again after failure.
Instead of immediately terminating, the system:
- retries,
- repairs,
- or escalates the workflow.
Retry systems are foundational in production AI engineering.
Basic Retry Workflow
AI Generates Output ↓Validation Fails ↓Retry Triggered ↓AI Attempts Again
This dramatically improves reliability.
Why Retry Logic Matters
Large language models often succeed on:
- second,
- third,
- or refined attempts.
Minor prompt changes or validation feedback can significantly improve outputs.
Retries help recover from transient failures.
Validation-Driven Retries
One of the strongest patterns in:
PydanticAI
is validation-driven retries.
Workflow:
AI Generates Structured Output ↓Pydantic Validation ↓Validation Error ↓Retry With Feedback
This creates much more robust workflows.
Example Validation Schema
from pydantic import BaseModelclass Product(BaseModel): name: str price: float
If the AI produces invalid data:
- validation detects it automatically.
Simple Retry Concept
Pseudo-code:
for attempt in range(3): try: result = run_agent() validate(result) break except Exception: retry()
This is one of the most important patterns in production AI systems.
Types of AI Failures
Different failures require different recovery strategies.
1. Validation Failures
Examples:
- invalid JSON,
- missing fields,
- wrong types.
Best solution:
- retry with validation feedback.
2. Tool Failures
Examples:
- API unavailable,
- database timeout,
- failed function call.
Best solution:
- retry tool execution,
- or fallback to alternative tools.
3. Hallucination Failures
Examples:
- fabricated information,
- incorrect claims,
- fake citations.
Best solution:
- retrieval validation,
- human review,
- or external verification.
4. State Corruption
Examples:
- missing workflow state,
- invalid memory,
- synchronization errors.
Best solution:
- restore checkpoints,
- or rebuild state safely.
5. Orchestration Failures
Examples:
- broken agent coordination,
- failed transitions,
- incomplete workflows.
Best solution:
- supervisory recovery logic.
Retry Strategies
Not all retries work the same way.
Fixed Retries
Retry a fixed number of times.
Example:
Maximum retries = 3
Simple and common.
Exponential Backoff
Wait progressively longer between retries.
Example:
Retry 1 → wait 1 secondRetry 2 → wait 2 secondsRetry 3 → wait 4 seconds
Useful for:
- API rate limits,
- network instability,
- temporary outages.
Adaptive Retries
The system changes behavior after failures.
Example:
- simplify prompts,
- reduce tool complexity,
- switch models,
- or alter workflow paths.
Retry with Error Feedback
Example:
Validation Error:price must be a float
The AI receives the error and tries again.
This often improves output quality significantly.
Failure Recovery vs Simple Retries
Retries alone are not enough.
Recovery systems may also:
- rollback workflows,
- restore checkpoints,
- escalate to humans,
- or switch strategies entirely.
Recovery Workflow Example
Agent Fails ↓Retry Attempt ↓Still Fails ↓Fallback Strategy ↓Human Escalation
This creates much safer systems.
AI Agents Need Graceful Failure
Production AI systems should:
- fail safely,
- recover intelligently,
- and remain observable.
Graceful failure handling is a major engineering discipline.
Structured Outputs Improve Recovery
Typed schemas make recovery easier because:
- failures become explicit,
- validation becomes deterministic,
- and debugging becomes clearer.
This is one reason structured AI systems are becoming so important.
Example Structured Error Model
class AgentError(BaseModel): error_type: str message: str retryable: bool
Structured errors improve:
- monitoring,
- logging,
- and orchestration.
Retry Logic and Multi-Step Agents
Multi-step workflows require:
- step-level retries,
- partial recovery,
- and checkpointing.
Example:
Step 1 succeedsStep 2 failsRetry Step 2 only
This prevents restarting entire workflows unnecessarily.
Retry Logic and Multi-Agent Systems
In multi-agent architectures:
- one agent may fail while others continue.
Recovery systems may:
- reassign tasks,
- restart failed agents,
- or reroute workflows.
This becomes increasingly important in distributed systems.
Human-in-the-Loop Recovery
Sometimes the safest recovery strategy is:
- human escalation.
Example:
Repeated Failure ↓Human Review Required
This prevents uncontrolled autonomous failures.
Observability and Monitoring
Production AI systems require strong observability.
Important metrics include:
- retry counts,
- failure rates,
- validation errors,
- tool failures,
- and workflow interruptions.
Without monitoring:
- reliability becomes difficult to improve.
Logging AI Failures
Good systems log:
- prompts,
- outputs,
- validation errors,
- tool calls,
- retries,
- and workflow states.
This dramatically improves debugging.
Why Python Developers Should Care
Python already has excellent tooling for:
- retries,
- async execution,
- monitoring,
- orchestration,
- and structured validation.
This makes Python ideal for resilient AI systems.
Common Beginner Mistakes
1. Assuming AI Outputs Are Always Correct
Validation and retries are essential.
2. Crashing Entire Workflows on Small Errors
Partial recovery is often possible.
3. Ignoring Observability
Without monitoring:
- failures remain invisible.
4. Overcomplicating Recovery Too Early
Start simple:
- validation,
- retries,
- logging,
- and fallback logic.
Real-World Use Cases
Retry and recovery systems are critical in:
- AI agents,
- workflow orchestration,
- coding assistants,
- retrieval systems,
- enterprise automation,
- research pipelines,
- and autonomous execution systems.
The Bigger Industry Trend
Modern AI engineering is rapidly evolving toward:
- resilient workflows,
- observability,
- recovery systems,
- and fault-tolerant architectures.
Reliability is becoming one of the most important challenges in production AI.
AI Reliability Is a Systems Problem
A major realization in AI engineering is:
Reliable AI is not just about better models.
It is also about:
- orchestration,
- validation,
- retries,
- monitoring,
- and recovery design.
System architecture matters enormously.
What You Should Learn Next
Recommended next tutorials:
- Retrieval-Augmented Generation (RAG) Explained
- Parsing LLM Responses Safely
- AI Output Validation Strategies
- Agent Orchestration with LangGraph
- Observability for AI Systems
These topics build directly on resilient AI engineering.
Final Thoughts
AI agent retry logic and failure recovery are foundational concepts in production AI systems.
Real-world AI applications must expect:
- failures,
- interruptions,
- hallucinations,
- and invalid outputs.
The most important difference between:
- fragile AI demos
and:
- reliable AI systems
is often the quality of their recovery architecture.
By combining:
- validation,
- retries,
- structured outputs,
- observability,
- and graceful recovery workflows,
developers can build AI systems that are:
- safer,
- more resilient,
- and more production-ready.
Frameworks like Pydantic AI strongly support these patterns because:
- typed schemas,
- validation layers,
- and structured workflows
make recovery logic dramatically easier to implement and maintain.
As AI systems become more autonomous and complex, failure recovery will become one of the most important disciplines in AI engineering.
