Error Handling in Structured AI Workflows
As AI systems become more integrated into:
- APIs,
- automation pipelines,
- multi-agent systems,
- enterprise workflows,
- and production infrastructure,
one reality becomes unavoidable:
AI systems fail.
Large language models can:
- hallucinate,
- generate malformed outputs,
- call tools incorrectly,
- lose workflow state,
- fail validation,
- hit API limits,
- or produce logically inconsistent responses.
This is completely normal.
The key challenge in production AI engineering is not:
- preventing every failure,
but:
- handling failures safely and predictably.
This is where error handling becomes critically important.
Frameworks like PydanticAI strongly emphasize:
- structured outputs,
- validation,
- typed workflows,
- and controlled orchestration
because these patterns dramatically improve error handling.
This article explains:
- why AI workflow failures happen,
- common structured AI errors,
- error handling strategies,
- and how Python developers can build more resilient AI systems.
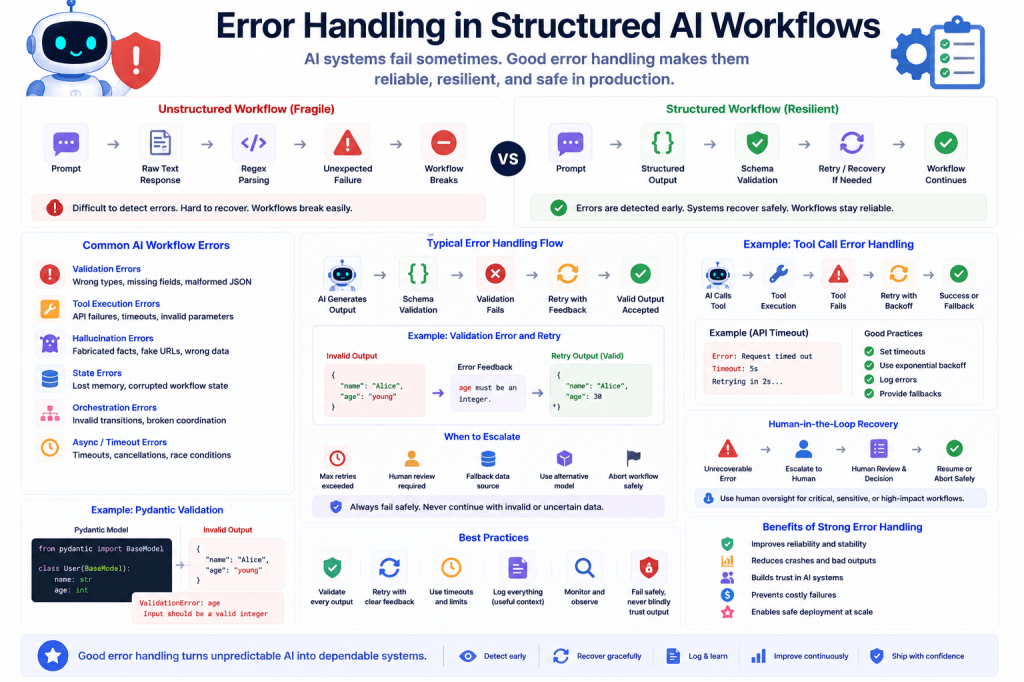
What Is Error Handling?
Error handling means:
- detecting,
- managing,
- recovering from,
- and safely responding to failures.
Instead of:
- crashing workflows,
robust systems:
- retry,
- recover,
- escalate,
- log,
- or gracefully fail.
Why Error Handling Matters in AI Systems
AI systems are probabilistic systems.
Unlike traditional deterministic software:
- outputs vary,
- reasoning may drift,
- and workflows may become unpredictable.
Production AI systems must therefore expect:
- uncertainty,
- malformed outputs,
- and orchestration failures.
Structured Workflows Improve Error Handling
One of the biggest advantages of structured AI systems is:
- failures become easier to detect.
Example:
class Product(BaseModel): name: str price: float
If the AI returns:
{ "name": "Laptop", "price": "cheap"}
Validation immediately detects the problem.
Structured workflows create explicit failure boundaries.
Unstructured vs Structured Error Handling
Unstructured Workflow
Prompt ↓Raw Text ↓Regex Parsing ↓Unexpected Failure
Errors become:
- difficult to debug,
- inconsistent,
- and fragile.
Structured Workflow
AI Output ↓Schema Validation ↓Controlled Error Handling ↓Retry or Recovery
Failures become:
- observable,
- manageable,
- and recoverable.
Common AI Workflow Errors
Production AI systems encounter many kinds of failures.
1. Validation Errors
Examples:
- wrong data types,
- missing fields,
- malformed JSON,
- invalid structure.
Example:
{ "price": "free"}
Expected:
price: float
2. Tool Execution Errors
Examples:
- failed API calls,
- database timeouts,
- unavailable services,
- invalid parameters.
3. Hallucination Errors
Examples:
- fabricated citations,
- fake URLs,
- invented database records,
- incorrect reasoning.
4. State Errors
Examples:
- lost memory,
- corrupted workflow state,
- incomplete execution history.
5. Orchestration Errors
Examples:
- broken multi-agent coordination,
- invalid workflow transitions,
- dead-end execution paths.
6. Async Execution Errors
Examples:
- timeout failures,
- cancelled tasks,
- race conditions,
- concurrency issues.
Why Structured Outputs Help
Structured outputs create:
- predictable contracts.
This makes:
- validation,
- retries,
- logging,
- and recovery
much easier.
This is one reason structured AI engineering is becoming so important.
Error Detection
The first step in error handling is:
- detecting problems early.
Validation systems help identify:
- invalid outputs,
- schema mismatches,
- and malformed responses
before workflows continue.
Validation-Driven Error Handling
One common architecture:
AI Generates Output ↓Schema Validation ↓If Invalid → Retry
This dramatically improves workflow reliability.
Example Pydantic Validation
from pydantic import BaseModelclass User(BaseModel): name: str age: int
If the model generates:
{ "name": "Alice", "age": "young"}
Pydantic raises:
- a validation error automatically.
Retry-Based Recovery
One of the most common recovery patterns.
Workflow:
Validation Error ↓Retry Prompt ↓Corrected Output
LLMs often succeed on:
- second,
- or refined attempts.
Retry with Error Feedback
Example:
Validation Error:age must be integer
The AI receives feedback and retries.
This often improves reliability significantly.
Fallback Strategies
Sometimes retries fail repeatedly.
Fallback systems may:
- simplify workflows,
- switch models,
- use cached data,
- or escalate to humans.
Human-in-the-Loop Error Recovery
For critical systems:
Repeated Failure ↓Human Review Required
This prevents dangerous autonomous execution.
Structured Error Models
Production systems often use structured error objects.
Example:
class WorkflowError(BaseModel): error_type: str message: str retryable: bool
This improves:
- monitoring,
- orchestration,
- and observability.
Error Handling and Tool Calling
Tool execution especially requires robust error handling.
Example:
AI Calls API ↓API Timeout ↓Retry or Fallback
Without recovery logic:
- workflows become brittle.
Error Handling and Multi-Step Workflows
Multi-step agents require:
- step-level recovery.
Example:
Step 1 succeedsStep 2 failsRetry only Step 2
This prevents restarting entire workflows unnecessarily.
Error Handling and Multi-Agent Systems
Multi-agent architectures introduce additional complexity.
Possible failures:
- communication breakdowns,
- invalid shared state,
- failed task routing,
- synchronization issues.
Structured orchestration improves recovery.
Error Handling and Async Systems
Async workflows introduce:
- concurrency failures,
- timeout handling,
- task cancellation,
- and coordination challenges.
Robust async systems require:
- careful orchestration design.
Timeout Handling
Production AI systems should never:
- wait indefinitely.
Example:
await asyncio.wait_for(task(), timeout=5)
Timeouts prevent:
- stalled workflows,
- and blocked orchestration.
Logging and Observability
Reliable systems log:
- prompts,
- outputs,
- validation failures,
- retry counts,
- tool failures,
- and workflow state.
Without observability:
- debugging becomes extremely difficult.
Why Observability Matters
Observability allows developers to:
- identify bottlenecks,
- detect unstable workflows,
- improve prompts,
- and refine recovery logic.
Modern AI systems increasingly require:
- production-grade monitoring.
Error Handling and Security
Error handling is also a security mechanism.
Validation and controlled workflows help prevent:
- malformed requests,
- unsafe execution,
- prompt injection propagation,
- and corrupted state.
Why Python Developers Should Care
Python already has excellent tooling for:
- retries,
- validation,
- async execution,
- logging,
- APIs,
- and orchestration.
This makes Python ideal for:
- resilient AI engineering.
Common Beginner Mistakes
1. Assuming AI Outputs Are Always Correct
Always validate outputs.
2. Crashing Entire Workflows on Small Errors
Partial recovery is often possible.
3. Ignoring Logging
Observability is essential in production systems.
4. Overengineering Recovery Too Early
Start with:
- validation,
- retries,
- and structured logging.
Real-World Use Cases
Structured error handling is critical in:
- AI agents,
- workflow orchestration,
- coding assistants,
- retrieval systems,
- enterprise automation,
- analytics pipelines,
- and autonomous systems.
The Bigger Industry Trend
Modern AI engineering is rapidly moving toward:
- resilient workflows,
- validation-first architectures,
- observability,
- and fault-tolerant orchestration systems.
Reliability is becoming one of the biggest priorities in production AI.
Reliability Is an Architectural Discipline
A major industry realization is:
Reliable AI systems are not created through prompts alone.
They require:
- schemas,
- validation,
- retries,
- orchestration,
- monitoring,
- and structured recovery systems.
Architecture matters enormously.
Why Pydantic AI Fits This Trend
PydanticAI strongly supports:
- typed schemas,
- structured outputs,
- validation,
- and predictable workflows.
This makes:
- error detection,
- recovery,
- and debugging
much easier compared to fragile text-only systems.
What You Should Learn Next
Recommended next tutorials:
- Observability for AI Systems
- Building Production AI APIs
- Retrieval-Augmented Generation (RAG) Explained
- Advanced Tool Calling with Pydantic AI
- Async Orchestration for AI Agents
These topics build directly on resilient workflow engineering.
Final Thoughts
Error handling in structured AI workflows is one of the most important disciplines in modern AI engineering.
Production AI systems must expect:
- invalid outputs,
- hallucinations,
- API failures,
- orchestration issues,
- and workflow interruptions.
The difference between:
- fragile AI demos
and:
- reliable AI systems
often comes down to the quality of:
- validation,
- retries,
- observability,
- and recovery architecture.
Frameworks like Pydantic AI strongly embrace structured workflows because:
- typed schemas,
- validation systems,
- and controlled orchestration
dramatically improve AI reliability.
As AI systems become increasingly integrated into:
- enterprise infrastructure,
- APIs,
- automation systems,
- and autonomous workflows,
structured error handling will become even more critical.
Reliable AI systems are built on reliable recovery systems.
